

QTrade语义解析背后的黑科技
摘要:
2021年6月,QTrade AI研究中心与香港中文大学(深圳)、华盛顿大学、深圳大数据研究院联合研究的四篇“语义识别及信息抽取”相关学术论文被收录于ACL会议(全称The Association for Computational Linguistics)。创办近半世纪以来,ACL已成为人工智能自然语言处理领域最顶级、最权威的国际学术会议组织之一,吸引着全球渴望征服人工智能(AI)皇冠明珠的代代科学家。而近年来,QTrade在自然语言处理算法能力上持续获得ACL的关注与追随;此次四篇文章的发表,是ACL对QTrade在AI研究成就上的果断认可,也将成为QTrade所服务行业的一次技术性突破。
正文:
QTrade,是腾讯旗下领先的金融科技与监管科技公司,致力于为金融固定收益行业提供专业化、智能化的交易解决方案。以腾讯的即时通讯工具(IM)为入口、金融市场实时行情数据为依托、AI语义解析能力为核心,QTrade通过深耕固收市场交易业务流程、深挖交易痛点,搭建了以连接市场、提升效率、发现价值、满足合规为四大价值体系的产品版图,为固收市场及从业者提供自动化、集成化的智能平台服务。
国内外金融固定收益市场因其“无指定集中交易场所”的特殊性及一对一询价的交易方式,在债券发行、交易和洽谈磋商阶段,高度依赖即时通讯工具(IM),强社交属性与好友(交易对手)关系链已成为固收市场的基础。以关系链为基础,逐步将聊天中的非结构化工作流、交易流和数据结构化呈现,将“聊天信息自动订单化”,是提升交易效率的关键,也是中国固收市场迈向智能交易重要一步。因此,AI算法已成为QTrade平台赋能各业务场景的核心纽带。基于特定的AI算法,QTrade为一级债券发行及销售、二级债券交易、资金交易、做市商等业务流程定制了不同的智能解决方案。
比如,在一级债投标的过程中,QTrade AI机器人助手会将债券销售与投资机构进行的实时聊天进行自动理解、识别,并整理成标准的投标标准化信息。当然,QTrade AI机器人助手不仅只服务于投标环节,也能理解“主人们”的改标、撤标意愿,并会自动屏蔽、过滤掉“主人们”的闲聊信息,不会打听主人们的小秘密哦。
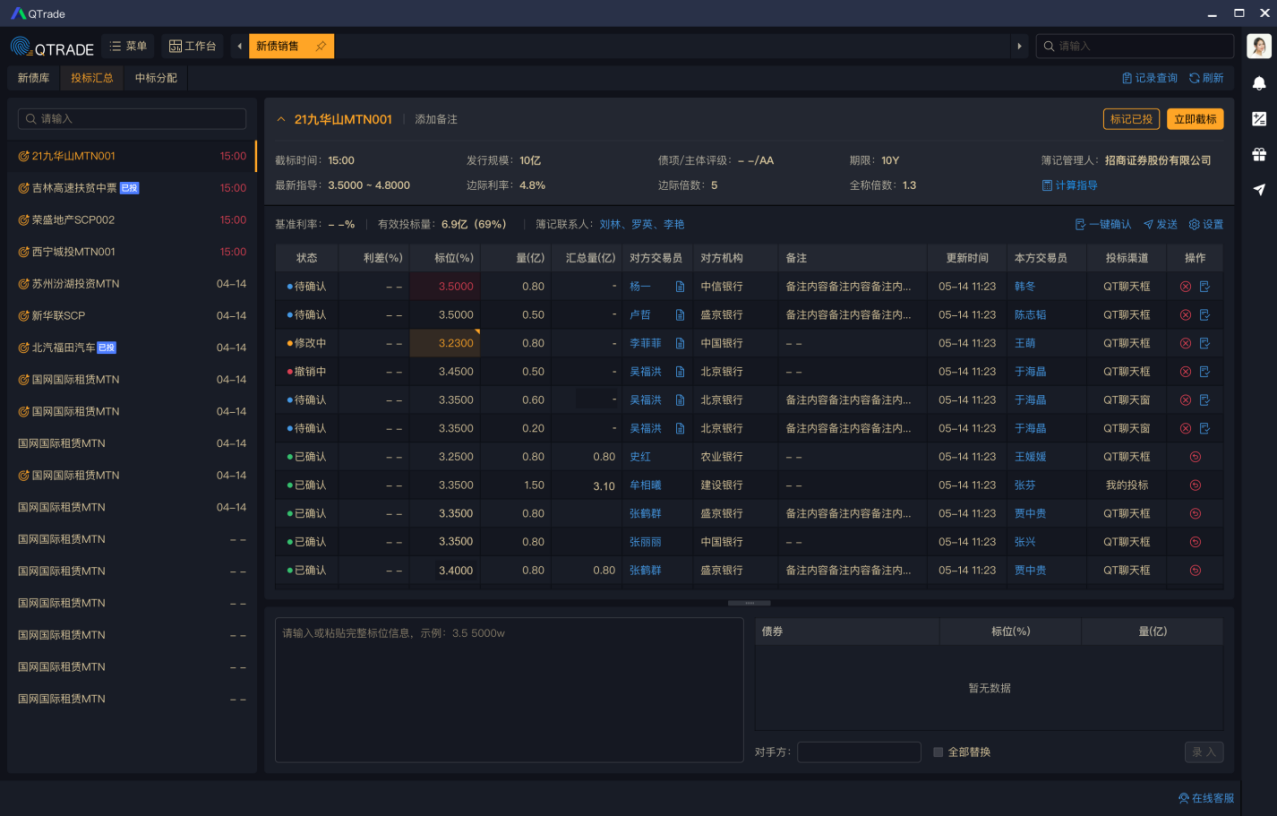
图1:债销Q交易汇总工作台
在资金交易、债券二级市场交易流程中,QTrade AI机器人助手不仅能识别“主人们”是在闲聊亦或谈业务,还能细分“主人们”的询价、成交、头寸管理等动作,并进行相应的分类整理,帮“主人们”把聊天信息整理成标准化格式,以供后续的统计分析、下行到交易系统,极大地减轻了“主人们”的工作负担。

图2: 交易Q现券汇总工作台
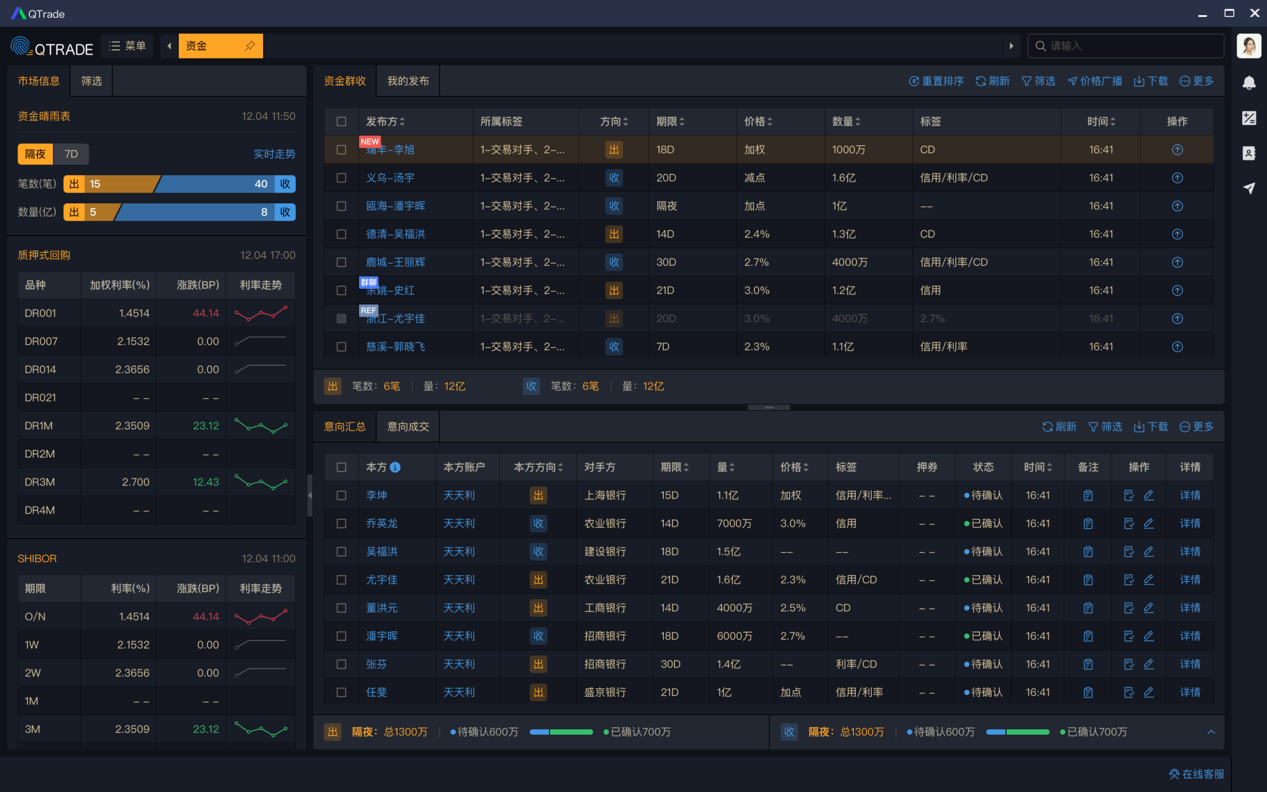
图3:资金交易汇总工作台
这些智能辅助功能背后的核心,就是AI领域的自然语言处理算法能力,包括语义识别、文本分类和信息抽取、文本结构化等相关算法。
用户的聊天信息,会通过AI助手内的一个文本分类算法模型,判断“主人们”聊天信息的不同意图。当识别出“讨论业务”的意图时,QTrade AI助手会把这个对话信息传到“信息抽取”模块,它是AI助手的核心,能把聊天对话中有价值的信息(如:债券代码、标位、标量、价格、期限、评级、等等)解析识别出来。
例如,当交易员说“把2.34%的撤了,另外21XXXXSCP001,2.45,3.2%各投2e 4.5kw,谢谢”,信息抽取模块会解析识别出“标位=2.34%,意图=撤标,债券简称=21XXXXSCP001,标位=2.45,标位=3.2%,意图=投标,标量=2e,标量=4.5kw”。这些信息会传到结构化和标准化模块,并被处理成表格结构形式(如下表);紧接着表格信息会被继续传到下一步的执行逻辑中,根据每条结构信息的要素和意图,自动化执行相应的投标、改标和撤标等操作。

表1: 左表是算法模型结构化后的结果;右表是将数据进行标准化后的结果
“文本分类”、“意图识别”和“信息抽取”等这些不明觉厉的东西,正是QTrade AI研究中心算法小伙伴们呕心沥血(熬夜加班)的成果!2021年初,QTrade AI研究中心陈桂敏同学联合各高校及研究所,共同提出了《基于依存句法驱动注意力图卷积神经网络的关系抽取》(ACL链接:https://aclanthology.org/2021.acl-long.344.pdf)、《基于词依存信息类型感知记忆神经网络的关系抽取》(ACL链接:https://aclanthology.org/2021.findings-acl.221.pdf)等最优算法模型,在各项公开数据集上已达到最优效果。
算法技术
金融交易的文本信息,不同于通用域具有明确主谓宾结构的文本。比如,一句买债请求“112345.IB 2.82%,3.45% 各投2e”包含了大量数字信息,采用通用域的某些语义分析模型,往往不能很好的理解文本的意图,亦无法有效提取其中的价值信息。
这个问题与阿拉伯语缺乏变音符号的文本书写具有一定的相似性。针对此问题,QTrade AI研究中心以阿拉伯语的公开数据集作为研究对象,提出了一种基于正则化解码联合对抗训练的方法,能够有效地区分外来知识的噪声,学习外来知识中对任务有用的部分,提升模型在变音任务上的性能。这套联合正则化解码和对抗训练的方法同样也提升了QTrade针对金融数据的模型学习能力和性能。
下图展示了模型如何通过正则化解码(RD)和对抗训练(AT)的方式学习自动生成知识,有效区分其中噪声,学习有用信息,提升模型的性能。

训练过程分成两个阶段。第一阶段,对于输入的每一个文本序列,利用工具自动生成序列中每个词的变音标签; 然后通过共享编码器、主标签解码模块的私有编码器和正则解码模块的私有编码器,分别提取序列的表征;接着,主标签解码模块基于表征进行解码,预测真实标签。从实验结果可以看出,该研究提取的正则解码联合对抗学习的方法能够有效提升模型的性能,在两个基准数据集的性能都超过了前人研究,达到目前最佳的成绩。【算法小哥哥建议感兴趣的同学参考文献(ACL链接:https://aclanthology.org/2021.acl-short.68.pdf)】

在语义理解上,中文分词是信息处理的基础任务之一。但在实际应用过程中存在数据孤岛,即数据被存储于不同的地方,因隐私或法律因素导致数据彼此不可见、互相孤立。而金融行业包含着大量彼此孤立的静态和动态数据,若不能及时解决数据孤岛的问题,对于机器学习会产生极大阻碍。针对此问题,QTrade AI研究中心提出了一种基于全局字符关联机制的神经网络模型(GCA-FL),通过联邦学习的方式,将彼此不可见且互相隔离的数据用于训练,提升模型在中文分词任务上的性能。其模型结构如下图所示(算法小哥哥再次建议感兴趣的小伙伴直接查看文献哦(ACL链接:https://aclanthology.org/2021.findings-acl.376.pdf)):

QTrade语义理解的核心是信息抽取模块,包括实体要素提取以及实体要素之间的关系提取。举个日常生活中简单的例子,我们说“小明和小丽的婚礼在海南三亚举行”,在这个句子中,“小明”、“小丽”是实体要素,他们的关系是可判断为“夫妻”,我们通过单个句子,可以很好地理解和提取以上信息。
在单一的句子级别中,句法信息(比如“依存句法“)被广泛应用于关系抽取任务,利用句法中有用信息帮助模型提升性能。QTrade AI研究中心采用了注意力图卷积神经网络模型A-GCN,基于剪枝的依存句法知识,对词与词之间的依存关系、以及关系类型进行上下文建模,通过注意力机制区分不同上下文特征的重要性,识别句法知识中的噪声,从而提升模型在关系抽取任务中的性能。模型结构如下图所示:

在A-GCN模块里,对于序列中的每一个词,将其与相关上下文词的依存关系和关系类型作为上下文特征进行编码;同时,为了区分不同上下文特征的重要性,采用注意力机制,通过计算词与词之间的点积,以此构建注意力矩阵(Attention Matrix),作为权重分配给其上下文特征,进而识别句法知识中的噪声,突出重要信息的作用。最后,基于A-GCN的输出,预测两个实体之间的关系标签。从实验结果可以看出,该研究提出的注意力图卷积神经网络模型在两个基准数据集上都超过了前人的研究,达到了目前最高的关系抽取任务成绩。

在对话场景,往往需要依赖上下文的多次对话或多段文本,才能对关键信息进行有效提取和判断。一种好的上下文信息建模机制,是通过融合外部知识,比如“依存信息“,才能够很好地提升该任务的性能。因此QTrade AI研究中心提出了基于词依存信息的类型映射记忆神经网络(Type-aware Map Memories,TaMM)的关系抽取模型,利用上下文关联词以及词与词之间的依存关系类型,对上下文信息进一步建模,也对上下文特征进行区分建模。其模型结构如下图所示:

在TaMM模块里,分别利用in-entity和cross-entity记忆槽(memory slots)融合键(上下文关联的词)和值(与词的依存关系类型)作为上下文特征;为了区分不同上下文特征的重要程度,采用了注意力机制,通过计算词和键之间的点积,作为权重分配给其上下文特征。最后,基于TaMM的输出,预测两个实体之间的关系标签。目前我们提出的类型映射记忆神经网络模型在两个基准数据集上超越了前人的研究,达到了目前最高的关系抽取任务成绩。

最后,让我们一起看看上述算法落地于实际业务场景中的成果吧,我们以一级债券销售为例:


当投资人跟主承或分销机构的伙伴们谈聊天交易的时候。我们的辅助交易系统会识别投资人发送的信息“21蚌埠高新 3.5 要5000w”是想要投“21蚌埠高新”这只债,标位是3.5%,投的金额是5000万。并且把它记录到债销Q系统上。基于上下文的关联解析算法,我们也能识别“改成 3.3 哈”识别是想对投的21蚌埠高新进行改标操作,并且提醒主承或分销机构的小伙伴们,投资人想要改标,已经记录了,请确认。
对于AI领域语义识别技术背后“黑科技”们的持续研究与探索,QTrade AI研究中心团队的小伙伴们将不遗余力;对于推动中国固收市场科技发展与生态建设、助力固收市场迈向新的时代,QTrade定将全力以赴。无论您是固收市场交易或IT从业者、是人工智能领域的工程师或研究员、亦或是我们初出茅庐的毕业生或智能技术狂热者,QTrade都欢迎您随时与我们沟通交流:
【商务咨询】了解QTrade产品功能并申请开通QTrade,QT号(同QQ号):2851703634
【产品咨询】深入探讨AI技术在固收交易领域的应用,并申请为机构定制智能交易解决方案:沙先生13817757642
【人才招聘】: 欢迎人工智能领域志同道合的你,加入QTrade AI研发中心:zhaopin@qtrade.com.cn
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

